Companies need to build an open IoT architecture that embraces a holistic approach to data and analytics that would allow them to see a complete overview of their entire production site.
“You need to integrate data from different sources into one holistic data platform. You also need an open and agnostic data pipeline that forwards your data from the devices to your platform,” said Philipp Redlinger, IoT architect at German-based System Vertrieb Alexander (SVA). “The pipeline needs to be able to integrate data from various sources in different formats. So, it has to be agnostic pipeline that you can expand for other protocols as well. And the platform has to be open on both sides in terms of ingestion as well as output. It must be capable of sharing data and insights with end-users via desktops and mobile clients. And, of course, it needs to be able to connect to other systems via a clearly structured API.”
“In order to enable interoperability and data-driven applications and end-to-end scenarios, such data pipeline in combination with an open platform is crucial,” he stressed.
Redlinger and his SVA colleague, IoT engineer Patrick Nieto Castro, were co-presenters during the “From Sensor To Cloud” session at last week’s .conf21 event organised by Splunk.
Redlinger added that the data pipeline of the IoT architecture should not only serve as “a simple data funnel that simply ingest all data” that cross its path.
“It should be capable of performing data processing such as transforming and filtering your data in order to increase the quality of your data at an early stage. And by turning raw data to refine data that is optimally prepared for your analytical applications, you will enable them to provide high-value insights for your business cases.”
Consequences of the silo issue
Gartner estimates that there will be 25 billion connected devices by the end of the year. And companies that have long ago deployed devices in various areas of their operations are now connecting them into an IIoT network with the hope mining the data in these devices to gain business insights to deliver new digital services.
According to Redlinger, isolated systems and fragmented solutions that now exist within organisations create a silo problem that prevent them from getting the total picture ,
“Due to these fragmented solutions, there are a lot of inefficiencies, and the systems vendor ultimately decides what happens to your data. You do not have sovereignty over your data. Because of this, it is very difficult to correlate data from sources and you cannot perform root cause analysis of multiple workstations, and you are missing the global perspective.”
The challenge of collecting IoT data for analysis has real consequences in terms of inefficiencies, outages and wastage, Redlinger pointed out.
“They are not just theoretical problems of missed opportunities due to the sophisticated use cases that you cannot implement. And there are also real money that is being lost basically every minute in countless ways.”
Citing a recent survey, he noted that people lost 30 minutes to two hours per working shift looking for the right data. On the positive side, a utility company in the US was able to cut the amount of outage minutes by 43.5% and reduce the cost by US$40 million a year after it dissolved legacy information silos and consolidate them in one holistic information platform.
Some ground rules before building an IoT architecture
Redlinger urged companies be realistic about technology, pointing out that architectures oftentimes are being built just for the sake of fancy technologies.
“Try to avoid this. Keep your strategies and business cases constantly aligned to your architecture,” he said. “Start with an MVP approach – start with minimum viable products. Keep it flexible and expandable so you can build on that later on.”
He also advised companies to accept that their requirements will change as the project progresses.
“Even if you try to get a perfect information upfront, your requirements will change by an estimated 1% per month. That is a rule of thumb. So even if you would know everything at the beginning, after one month of doing the project, your requirements would have already been different, so you need to constantly readjust.”
He stressed that there is no silver bullet, so build on open standards and consider hybrid scenarios. “And keep single parts of your pipeline exchangeable so you can make adjustments later on.”
Needless to say, do not compromise on security, Redlinger said.
“There are many strong mechanisms nowadays such as network segmentation, strong authentication mechanism, encryption and analytics-driven security – which is a strong one at Splunk.”
Connecting to the cloud
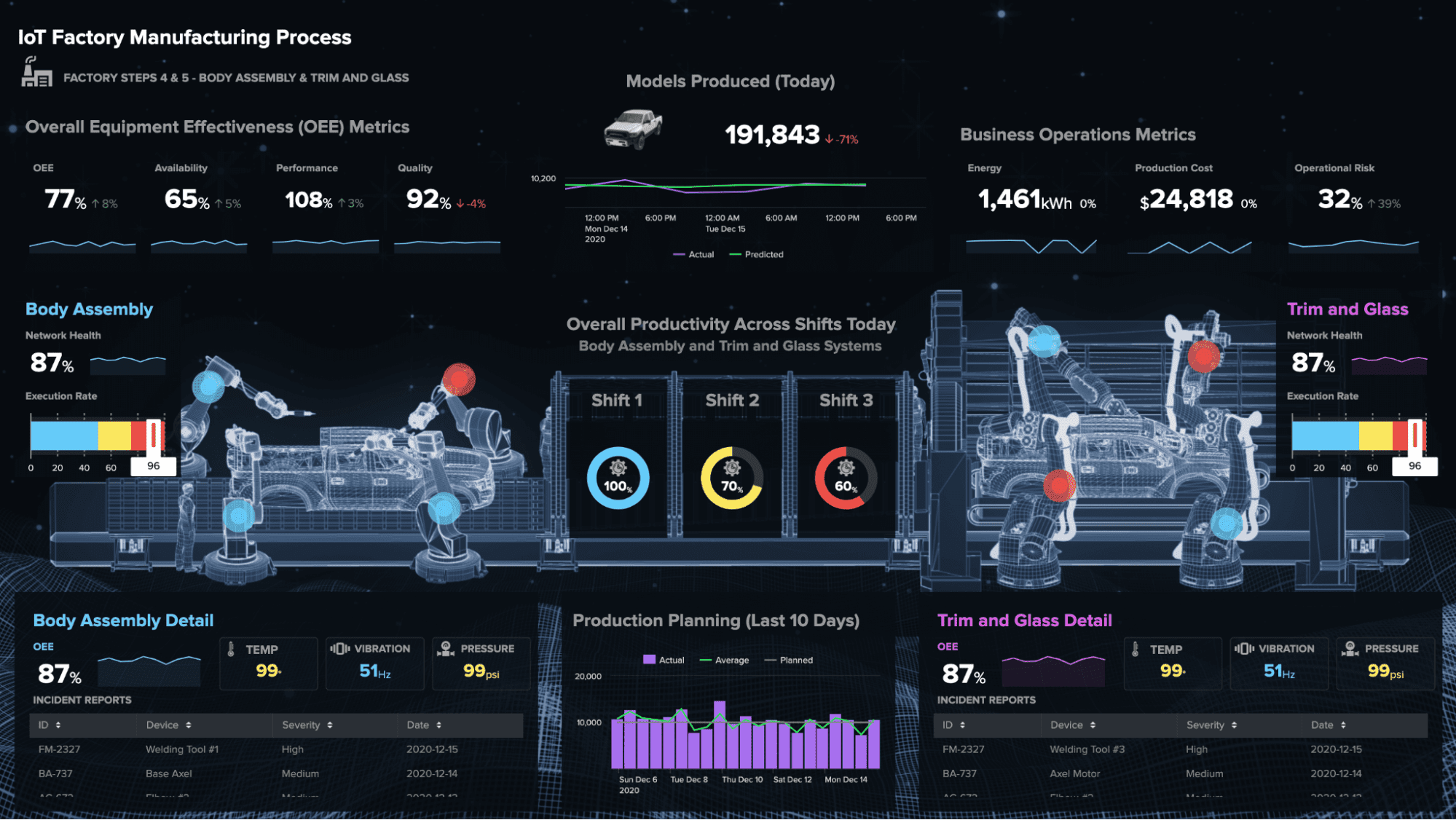
According to Redlinger, the quick start scenario for designing an IoT data pipeline is a direct integration with Splunk Cloud. And these can be done in several ways as shown below:
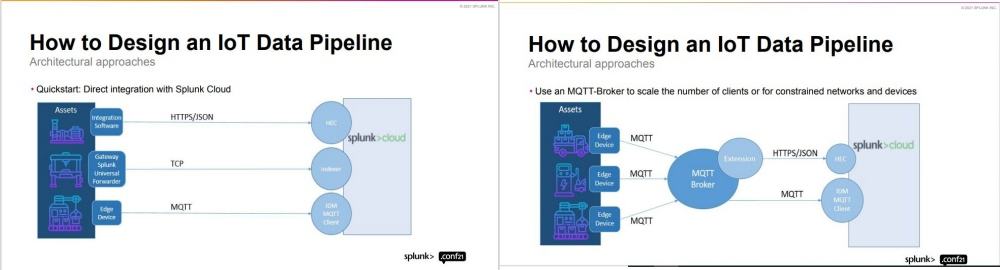
He enumerated the different components and protocols that are the building blocks: LP-WAN for connectivity when Wi-Fi and LTE is not an option; an edge hardware, which is typically an IoT gateway, but can be anything up to scalable edge-as-a-service platforms; and various legacy and proprietary machine protocols that need to be translated by middleware, which runs on edge Hardware or in the cloud or data centre.
He also listed the new protocols for the open IoT architecture.
“The OPC UA is the silver lining in the horizon because it is the first widely accepted open standard for machine interoperability, supported by most modern industrial equipment and software. So, keep your architecture somewhat compatible OPC UA as possible.
“And at the backend, we have the MQTT protocol, which is the open & lightweight Pub/Sub-Messaging Protocol. It is very useful in scenarios where there are a high number of connected devices or uneven network coverage – i.e., connected cars.
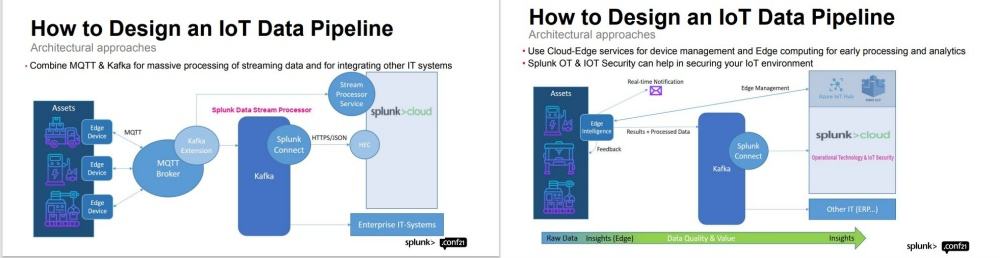
“And then we have the Apache Kafka, which is a fully blown distributed streaming platform. And that is very helpful if you need a central data hub for various applications and backend systems, and if you want to perform heavy workloads on your streaming data.”
Meanwhile, SVA IoT engineer Patrick Nieto Castro, the first step in building the IoT data pipeline is connecting all the actual devices.
Castro advise that companies should ensure that they clean their data and prepare their data as early as possible before sending them any further.
“Believe me, any data scientist you are possibly working with will surely be thankful if filter out any nulled values, any non-numeric values or any crappy data before handing it to them.”
Castro shared a real-life use case where SVA worked to create the IoT data pipeline for a company that runs electric vehicle charging stations in Germany.
“For the final architecture, I will try to put some name in the architectural building blocks. We use gateways of Insys Microelectronics, one of our partners for connectivity and edge computing, at each production site. The HiveMQ, enterprise MQTT broker as a reliable and scalable data turntable. Also, my colleagues and I developed our very own extension for sending telemetry data from HiveMQ MQTT broker to Splunk Cloud where the sensor data is connected and analysed.”
Onsite at each EV charging station, Castro gave a glimpse of what it takes to physically build the IoT data pipeline.
“We have to convert current and voltage to https. First, we connect our power consumer to a power relay, which is done via an electric wiring. This is an interesting step because of the high voltage. Next, we connect the power relay to a power meter, the sensor that effectively converts current and voltage into measurement. You all know this type of device because it is used to collect the electricity bill at your home by your local electricity supplier.
“And now we connect the power meter to an energy gateway by one of our partners. Insys Microelectronics is one of the market leaders in the energy supply markets. They make it possible to encode the data of power meters as serial signals. And we connect the central gateway to HiveMQ, an enterprise MQTT broker that converts digital signals into telemetry encrypted data. The central gateway has an internet connection and sends the telemetry data via MQTT using our very own extension to send telemetry data into Splunk Cloud.”
Benefits of the holistic approach to data and analytics
Redlinger said that once a company’s IIoT use case has matured enough and having a good idea of their analytical algorithms, then you can start deploying simplified versions of them right away on their edge devices.
“You have some kind of limited compute power that might be enough to run the simpler algorithms and then you can start generating insights right from the beginning where the data is generated. And you can have a very tight feedback loop. So, if one of your algorithms detect an error in your production system, it can halt the production and notify a shop floor operations person in order to fix the error. You have a very fast reaction time with this, and you can also use a lot of pre-processing at the edge that way,” Redlinger said.
Redlinger explained why Splunk is an ideal choice for building an IoT data pipeline: “Splunk has very strong self-service analytics capabilities. It is easy for normal users to learn how to run communities, how to build dashboards, how to explore data. And by hierarchical segmentation of dashboards, you can build apps and dashboards for management reports down to the operational level of having an overview for shop co-operators.
“And you have machine learning capabilities: you have the machine learning toolkit, the deep learning toolkit. You can integrate custom codes for custom app, so you can have all the data-driven analytics capabilities that you need. And in the cloud, it is fast and easy to start. You have low capital expenditure – an upfront investment but you can really start your journey very quickly – see it has proven value, then quickly scale it up and down if necessary.
“And it is also very easy as the data is already globally available in the cloud to share it with other parties and other systems to create third-party services as well.
Meanwhile, Castro identified benefits of adopting a holistic approach to data and analytics in IIoT deployments.
“The digital twins accelerate your business as never experienced before by increasing transparency of the day to day actions. Instead of sending over technicians to read out measurements, there is constant monitoring of device performance and conditions.
“We have the advantage of AIOps that train models to look for feature combinations which best explain your data. And we have predictive maintenance. You can forecast anomalies, machinery conditions, which effectively decreases unexpected downtime and increases the overall performance.”

